ABIS Infor - 2019-06
The new Hadoop software stack
Summary
Hadoop is an open source project that aims at providing a framework for large volume scalable & distributed data storage and computing. On top of this "base" framework, a number of additional open source products have been developed and are becoming very popular amongst Data Scientists. This set of tools is often called the "Hadoop Stack".
Since its initial release in 2006, Hadoop has been growing and evolving. And more importantly, the Hadoop Stack building blocks have drastically changed over time: some software products that were important and popular a few years ago have faded, while others entered the picture and some became so important that they currently are the real Hadoop! "front end"!
Hadoop "core"
The origins of Hadoop go back to the years 2003–2006, when Doug Cutting and Mike Cafarella re-implemented the Google distributed file system GFS and Google's MapReduce idea in Java within a web crawler project called Nutch. Since then, Hadoop continued to grow in functionality and in number of users and contributors, under the umbrella of the Apache Software Foundation: a not-for-profit organisation that currently hosts more than 350 open source software projects.
The main goal of Hadoop can be summarized as follows: it provides a stable layer, comparable to an operating system, for storing data (like a file system) and performing data manipulations (like a task scheduler), on top of a TCP/IP network of independent and potentially unreliable computers (called nodes) of a so-called computer cluster.
This distributed storage & computing layout allows for in principle unlimited upscaling, both in storage capacity and in parallel computing capacity. Also, hardware failures (e.g. crashed disks) are solved by just replacing that node.
Hadoop consists of three core building blocks:
- HDFS, the Hadoop Distributed File System. This abstraction layer gives the user a unix-style hierarchical file system, thereby hiding the details of (1) chopping large files into smaller partitions which are distributed over different nodes, and (2) providing hardware failure tolerance by duplicating each partition over multiple nodes (3 by default).
- MapReduce, the computational framework, allowing programmers to write their data processing algorithms in a parallellizable way, such that processing of different partitions of the input data can happen in parallel (i.e.: on different nodes at the same time) when that makes sense for the algorithm: this is the "Map" phase. The framework then does the necessary data shuffling between nodes before the final "Reduce" phase is run (typically not parallelized).
- Yarn, "yet another resource negotiator", the task scheduler which assigns jobs (i.e.: phases of MapReduce programs) to participating nodes with available (computing) resources, perferably those containing one of the three copies of the relevant input data file partition.
The Hadoop Stack
As you may find out by searching for the term "Hadoop stack", and more specifically for images for this search term and comparing older and newer images, the stack of software products (and more specifically: Apache products) that build on Hadoop is constantly changing. And each software vendor will of course have its version of the stack image, thereby highlighting the important place of its own software product in this context!
,
Let's try to be vendor neutral here, and concentrate on Apache products which are popular and generally considered useful. Below is the new Hadoop Stack, with what we at ABIS currently (2019) consider to be the most interesting Apache products that build on the mentioned three Hadoop core building blocks, either directly or indirectly.
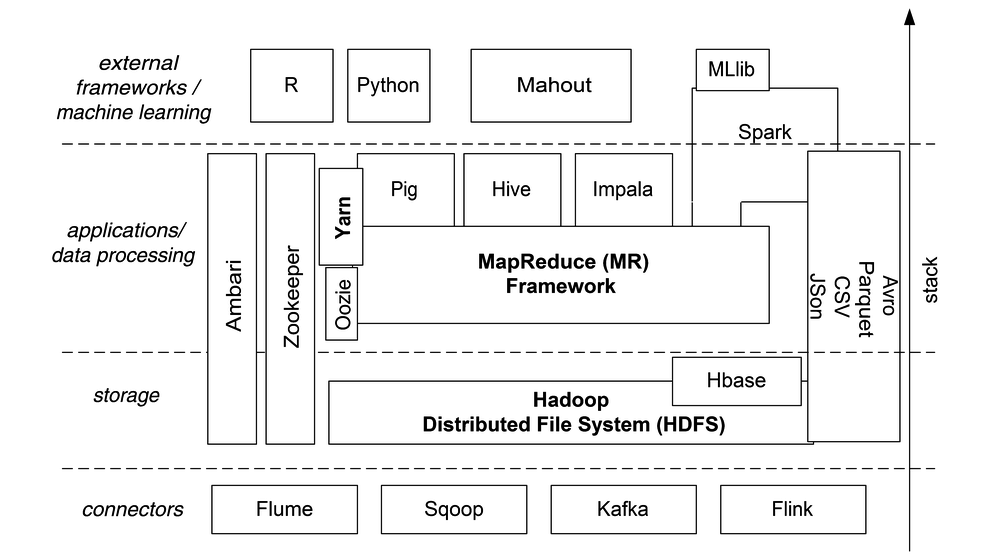
The building blocks in a nutshell
Apart from the three "base" Hadoop components (HDFS, MapReduce and Yarn), the building blocks can be roughly subdivided into four categories: connectors (to external data), storage (and file formats), data processing (which are mainly front-ends to MapReduce), and high-level applications (e.g. machine learning) and interfaces to programming languages.
- Flume is meant for streaming large volumes of log data and storing it efficiently on HDFS.
- Sqoop allows bulk data transfer between HDFS and relational databases. It may have become superfluous, though.
- Kafka is a very popular message broker, e.g. for streaming website activity tracking data into appropriate HDFS files.
- Also Flink is a stream processing framework; its main use case is running event-driven analytic applications.
- In the same "connector" category we could mention Avro and Parquet: those are actually file formats. Avro is actually a data serialization system, allowing to aggregate a wide variety of data (and metadata) into a binary file, and it can be used over an RPC client-server link. Also Parquet is a binary file format, but specifically targeted at tabular data as is typically needed by MapReduce jobs. CSV and JSON are also popular file formats, mentioned here just for completeness' sake: they are of course not Apache products, and are used in a much wider context than Hadoop's.
- Hbase is a NoSQL database management system (DBMS), one of many; but it's the only one within the Hadoop ecosystem, and specifically tied to HDFS. It's modeled after Google's proprietary Bigtable storage system.
- Ambari is an administrator tool for a Hadoop cluster: Ambari has a monitoring & alerting web-based dashboard, an easy web interface for starting & stopping nodes & services, and for installing/upgrading software onto all nodes.
- Zookeeper helps administrators in a different way: it maintains a central repository of configuration settings of all nodes in the cluster. This data is itself distributed, so "centralized" does not mean "single point of failure"!
- Oozie sits conceptually close to Yarn, but at an other phase of the job scheduling process: it allows an administrator to manage running jobs, and an end user to visualize data flows and dependencies between different job steps.
- Hive is the basic SQL front-end to Hadoop: it's exactly like an optimizer in a relational database system: it translates SQL queries into MapReduce jobs (possibly more than one job for one query), thereby abstracting away the low-level MapReduce algorithmic finesses from the end user.
- Pig is very similar to Hive: it translates a higher-level algorithmic description into lower-level MapReduce jobs. The Pig interface language allows to use named variables as placeholders for intermediate results (cf the RDDs of Spark).
- Impala goes a step further than Hive: it uses Hive where possible but is in the first place a high-level SQL query engine through which users may also interrogate HBase data or Parquet files.
- Spark is of a different scale than most of the already mentioned software products: it provides an all-in-one solution through a uniform end user experience, for functionality similar to that of Pig and Hive, plus extension libraries for stream processing and for machine learning. In addition, it allows to optionally store intermediate results (between MapReduce job steps) in memory, thereby potentially speeding up the processing considerably compared to e.g. Hive.
- Mahout is a machine learning environment on top of Hadoop, containing implementations for e.g. clustering and classification. Just like Pig and Hive, Mahout translates the user requests into Java code for MapReduce jobs. Note that Spark users would never use Mahout since Spark has a built-in alternative for Mahout, viz. its MLlib extension library.
- R is not an Apache product, and not tightly connected to Hadoop. Still it's worth mentioning since it's a popular open-source front end for processing large data collections, mainly amongst statisticians, and it's one of the few explicitly supported user interfaces for Spark. Apart from its statistical and graphical functionality, which makes it an interesting competitor for e.g. SPSS or SAS, R is popular because of its large collection of open-source libraries.
- Also Python is of course not an Apache project, but a well-known general pupose programming language. Just like R it became a very popular interface for data scientists thanks to its large collection of open-source libraries. Also Python is one of the explicitly supported user interfaces for Spark (next to R, Scala, and Java).
Actually, this list is far from complete, and new functionality and even new software is added while I'm writing this text... But as a start, you should certainly have a closer look at the above mentioned Apache products. It's worth the effort!
Conclusion
The Hadoop ecosystem is still a quickly evolving set of building blocks, altough is now seems to gradually stabilize. Want to know more? Please consult the list of ABIS courses on the subject!